Single Point Failure 指的是系統中如果某一個節點失效,整個系統都會停擺。當 Grafana 成為所有監控的核心時,如果 Grafana 發生異常,我們可能無法得知系統狀況,進而無法查找問題,直接被打回原始時代,只能翻閱伺服器上的 Log 來排查。因此,了解 Grafana 的架構並提高其可用性,對它進行有效的監控,是確保其穩定運行的重要一環。
Grafana 主要用於監控系統狀態,自己也提供 Monitoring 機制,讓我們能夠監控 Grafana 自身的狀態。啟用後,可以透過 /metrics endpoint 取得 Grafana 的 Prometheus Metrics。除了基礎的 Logs 與 Metrics 外,Grafana 也支援 OpenTelemetry,以查看各種 Trace 資料。
以下是 Metrics 和 Traces 的設定範例:
[metrics]
enabled = true
[tracing.opentelemetry.otlp]
address = tempo:4317
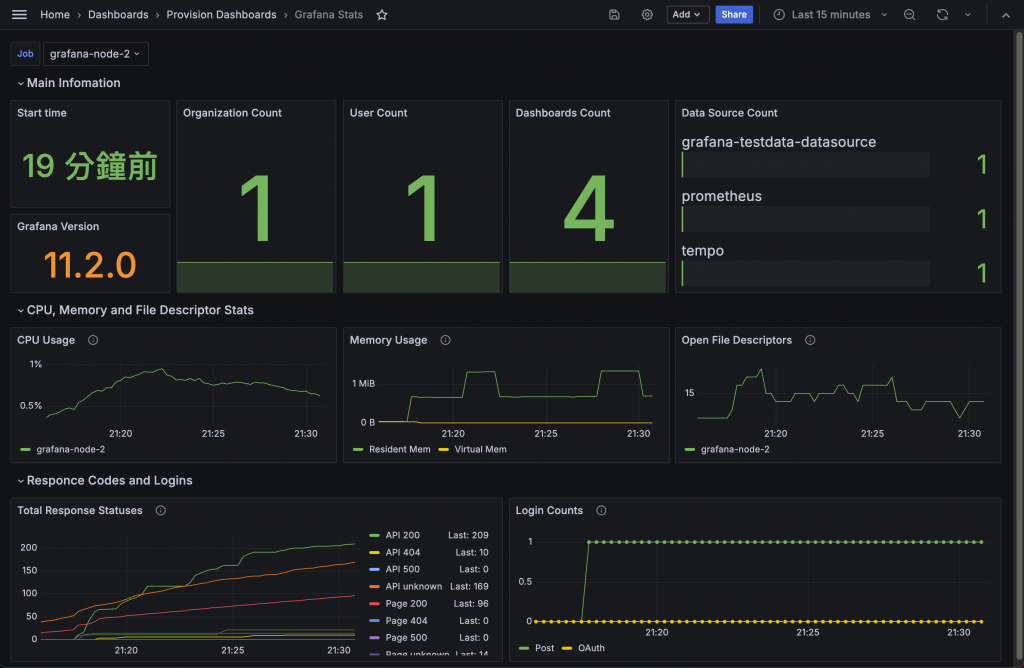
Grafana 的 Metrics Dashboard
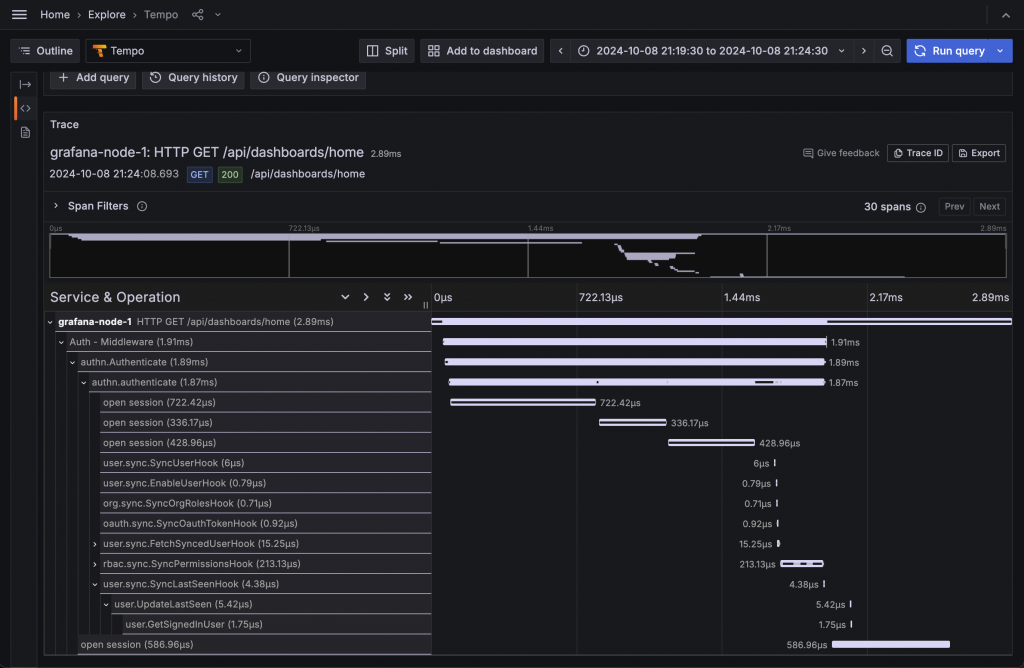
Grafana 的 Traces
現代微服務架構假設隨時可能發生故障,因此高可用性(High Availability, HA)架構能讓服務承受部分失效仍能正常運行。Grafana 也提供 HA 架構,架構如下圖所示。
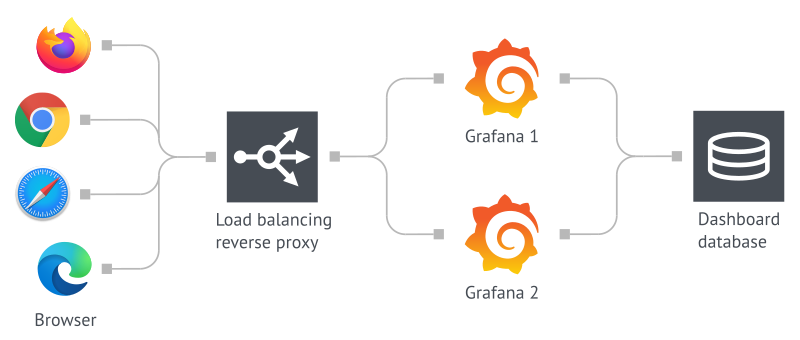
圖片來源:Grafana
在最基本的單體架構中,Grafana 是使用本地儲存的 SQLite 作為資料庫。因此,實現 HA 的第一步是抽離資料庫,Grafana 支援 MySQL 或 PostgreSQL 作為資料庫,設定可以在 database 中進行。抽離後,多個 Grafana Instance 可以共用一個資料庫,並由一個 Load Balancer 負責將請求分配至可用的 Grafana Instance。
使用 PostgreSQL 作為 Database 的設定範例如下:
[database]
type = postgres
host = postgres:5432
name = grafana
user = grafana
password = password
ssl_mode = disable
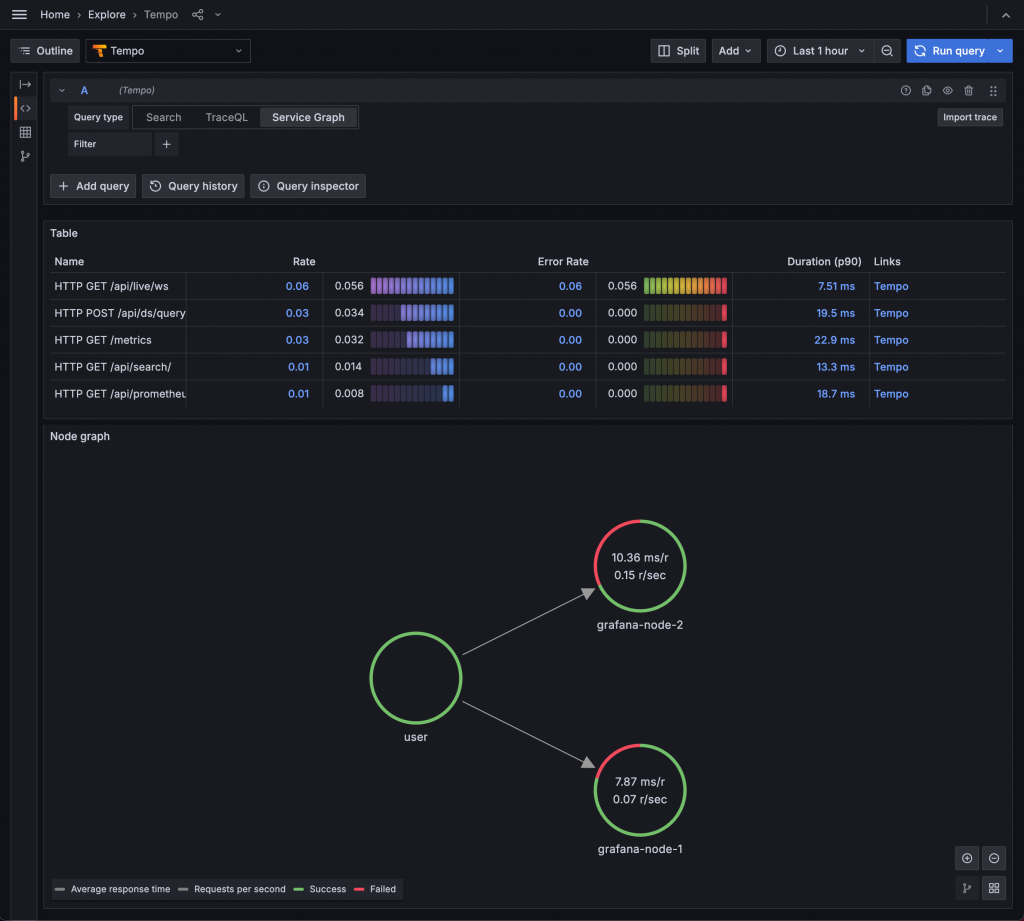
使用 Tempo 的 Node Graph 功能可以看到有兩個 Grafana Instance
如果 Load Balancer 或 Database 仍是單體架構,而沒有進行高可用性設計,那麼只會將 Single Point Failure 的風險轉移到了這兩個服務上。因此,常見做法是將這些關鍵組件也設計成 HA 架構,或直接使用雲端供應商內建的 HA 服務來確保可用性。
除了讓使用者隨時能查看 Dashboard 外,Alerting 的高可用性也是至關重要的,因為當 Grafana 出現故障時,會導致告警無法發送,讓使用者誤以為一切正常。Grafana 提供 Alerting HA 設定,讓多個 Grafana Instance 同步當前告警狀態,並確保只發送一份告警,避免 Grafana Instance 都各自送出一份告警造成洗版。
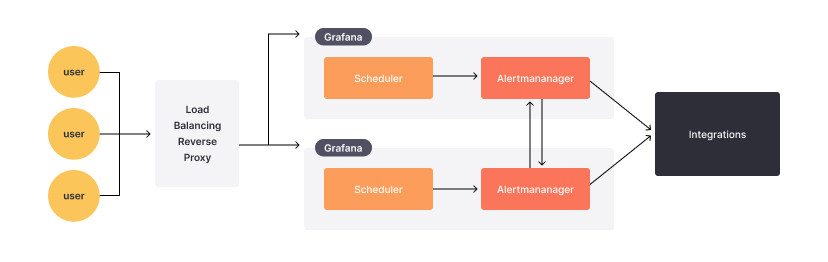
Grafana Alerting HA 示意圖,圖片來源:Grafana
在 unified_alerting 設定檔中,可以設定 Alert 的同步功能,並有兩種同步方式可供選擇:
9094 Port 互相通訊,交換哪些告警已經送出,避免重複發送。以下是 Redis 設定範例:
[unified_alerting]
ha_redis_address = redis_alerting_ha:6379
ha_redis_prefix = grafana_ha
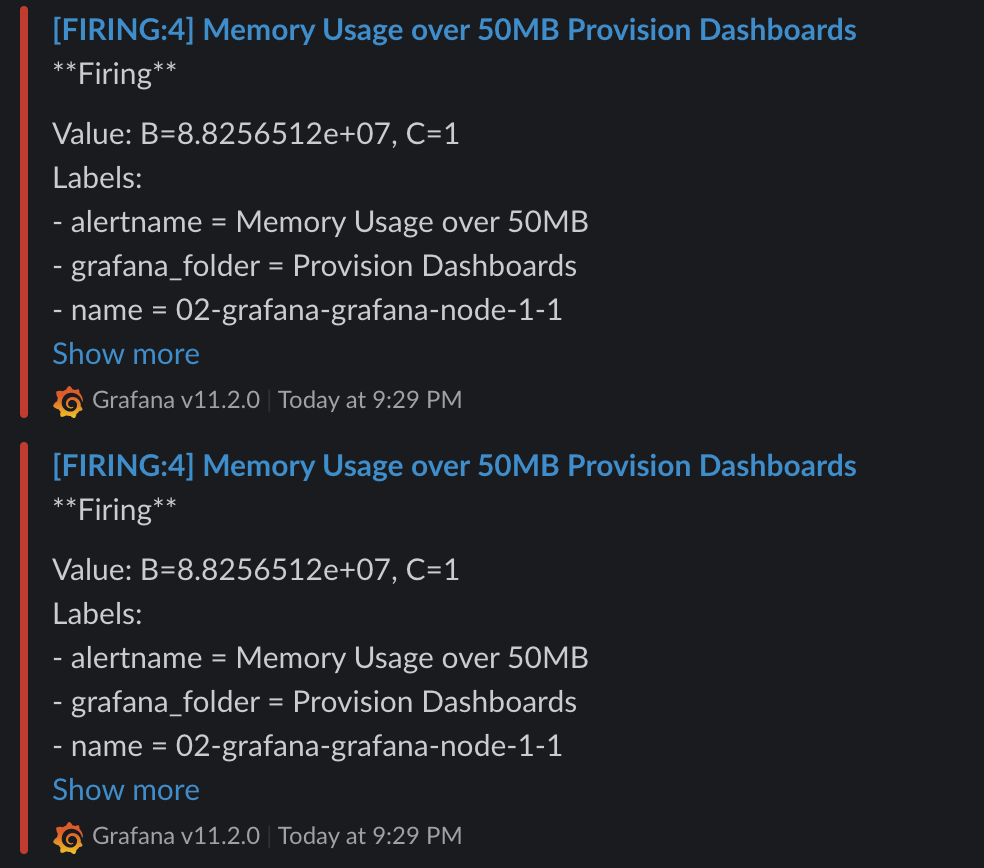
如果沒有設定 Alert HA,會導致重複發送告警
範例程式碼:https://github.com/blueswen/grafana-zero-to-hero/tree/main/07-management/02-grafana
此 Lab 會建立
啟動所有服務
docker-compose up -d
登入 Grafana 操作 Dashboard、Explore 功能與測試 Alert 是否有 HA 架構及不會重複發送
admin/admin
關閉所有服務
docker-compose down


 iThome鐵人賽
iThome鐵人賽